[1] "state" "race" "type"
[4] "all_workers_n" "artists_n" "artists_share"
[7] "location_quotient"Lab 5.
Small Multiples, Big Insights:
Maps & TidyTuesday in R
PUBH 6199: Visualizing Data with R, Summer 2026
2026-06-18
About me
Jahred Liddie, Postdoctoral Associate in the Water, Health, and Opportunity Lab at GWSPH
Research focuses: drinking water quality, exposure assessment, emerging contaminants, and environmental justice
Hobbies: flute, tennis, and playing with my dog, Georgette

What is #tidytuesday?
#tidytuesday is a weekly social data project organized by the Data Science Learning Community since 2018
Each Monday, a curated dataset is posted to their Github repo
Participants explore the data and share visualizations on social media (formerly on Twitter, now Bluesky)
Past example datasets
Bob Ross paintings
Weekly US gas prices
Stranger Things dialogue
A dataset of all Pokemon and their stats (available from the
pokemonpackage)

My very first plot
Key packages: cowplot, ggtext
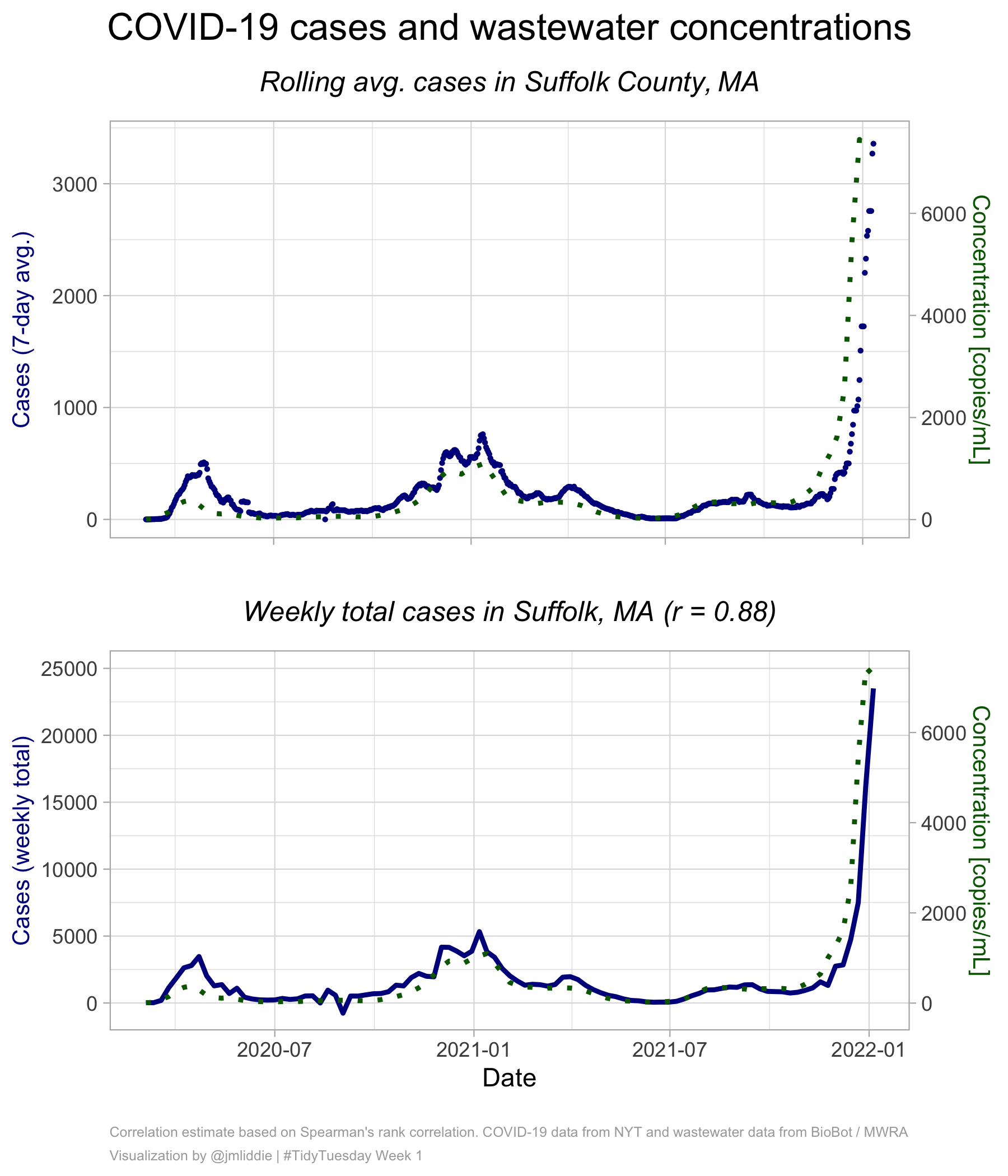
Other examples (pt 1)
Key packages: showtext, ggrepel
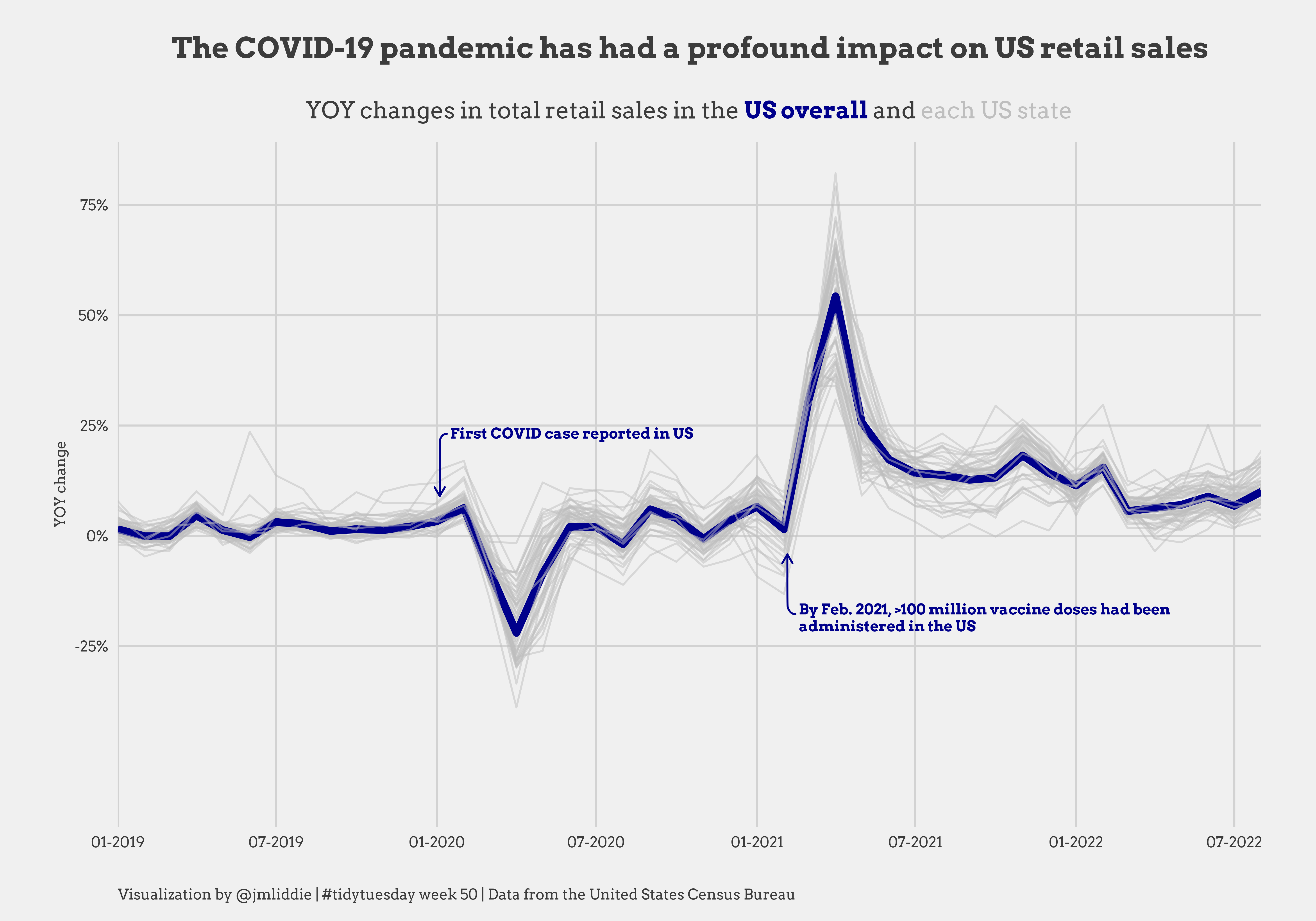
Other examples (pt 2)
Key packages: showtext, ggrepel
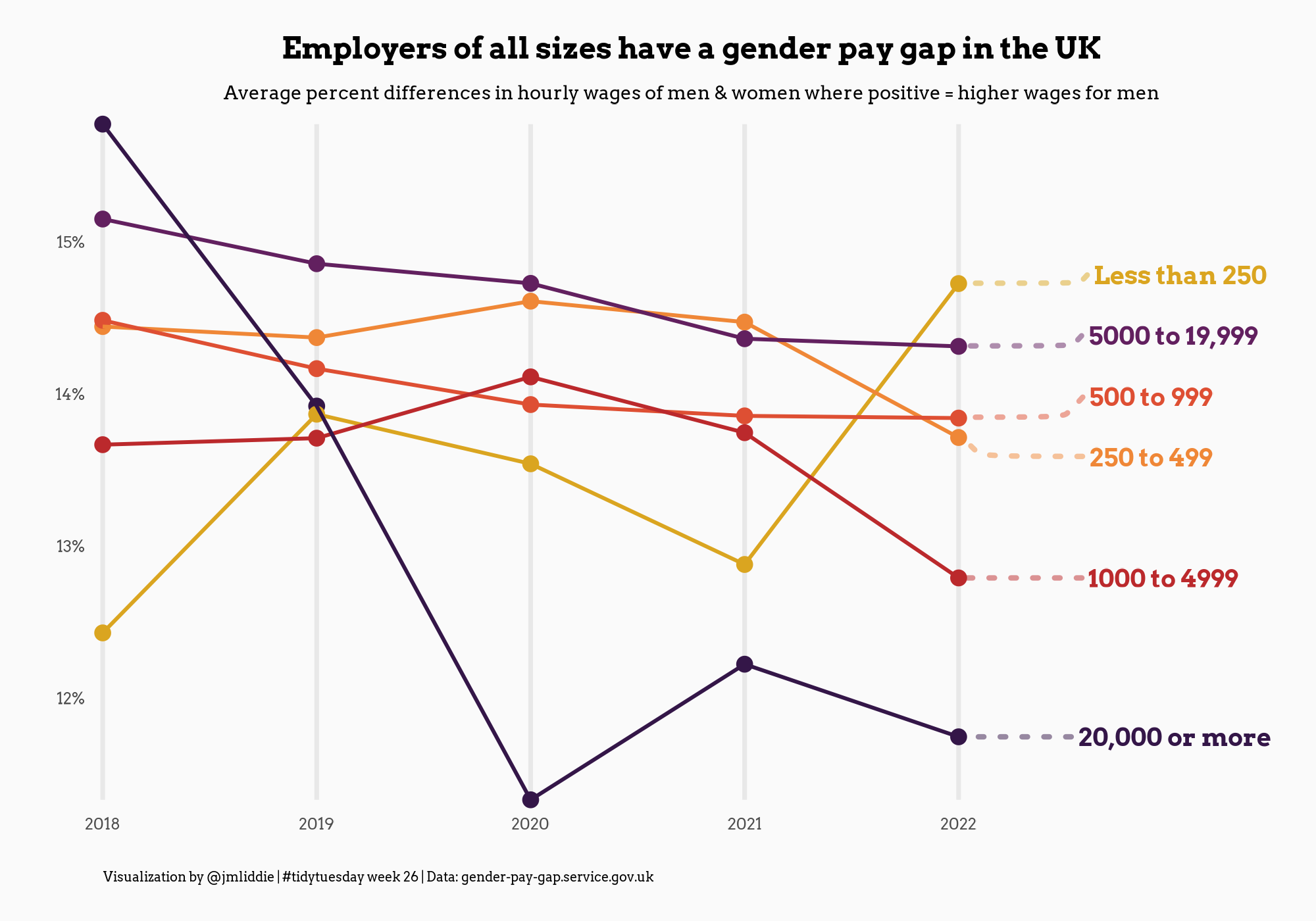
Other examples (pt 3)
Key packages: gganimate, ggtext
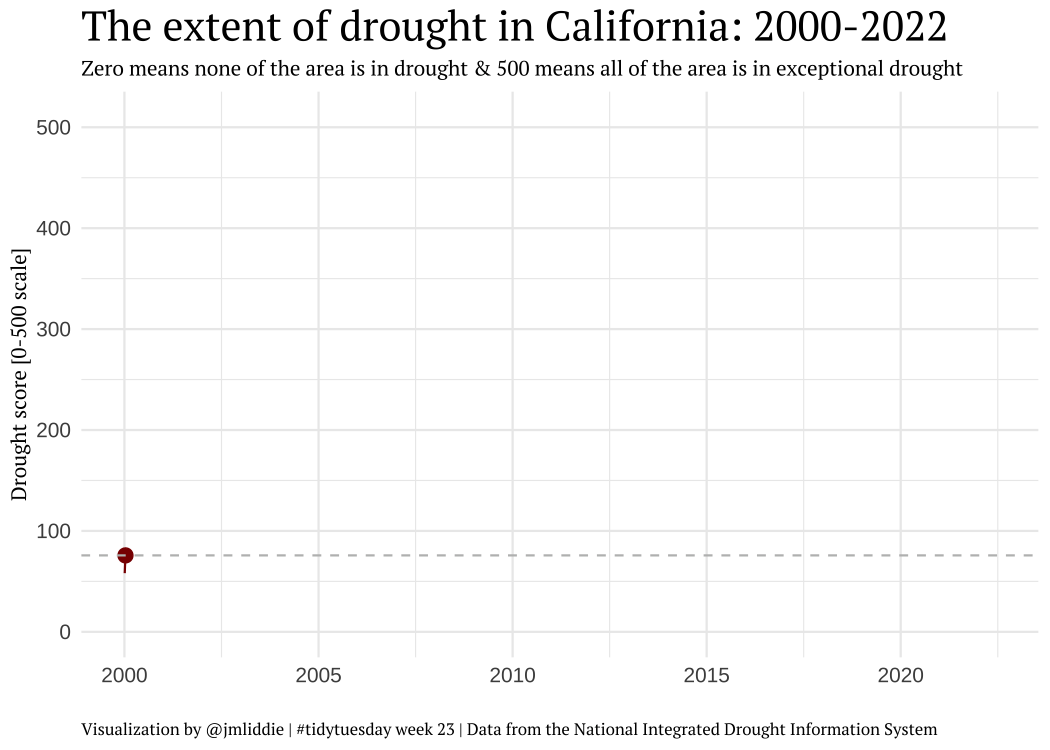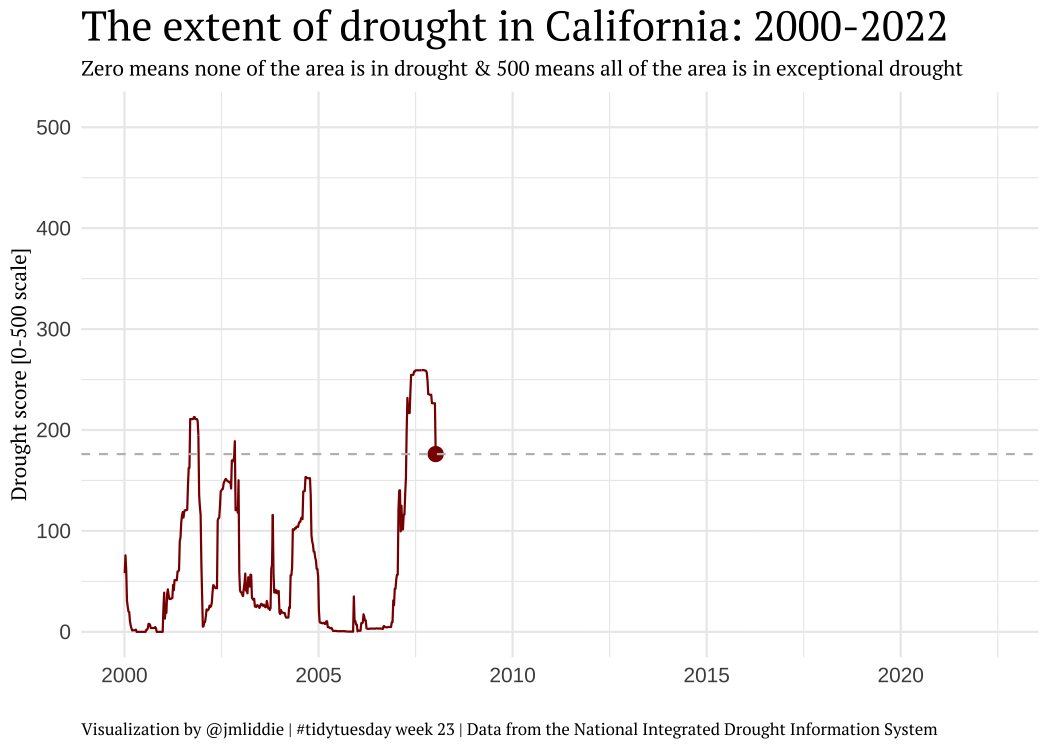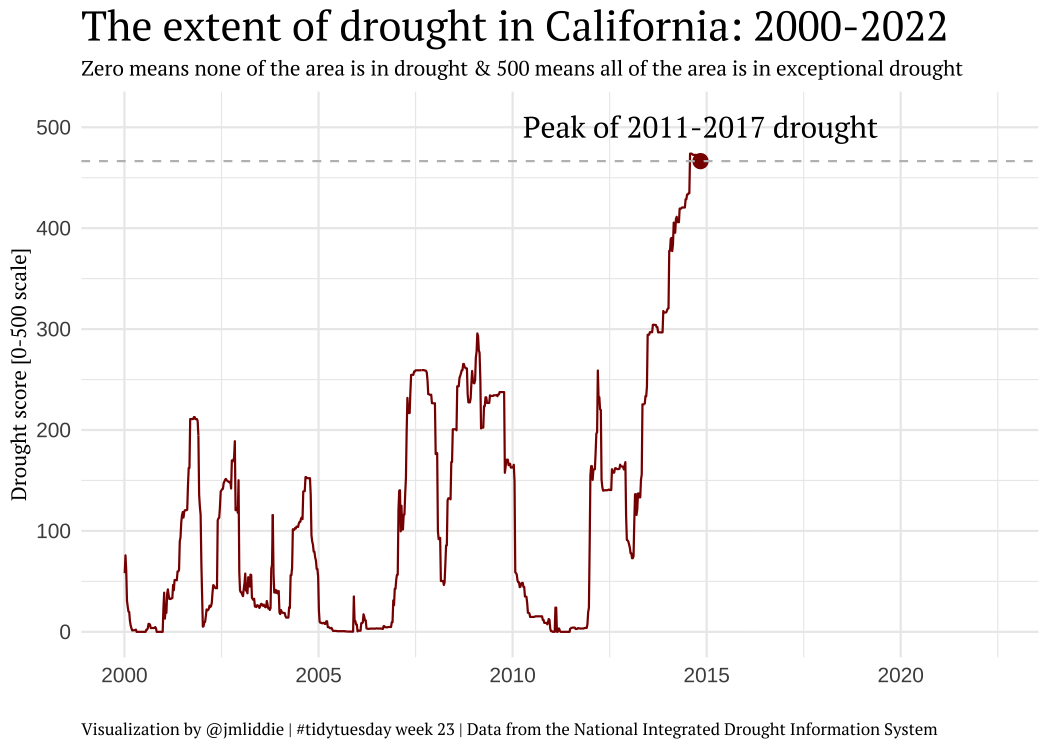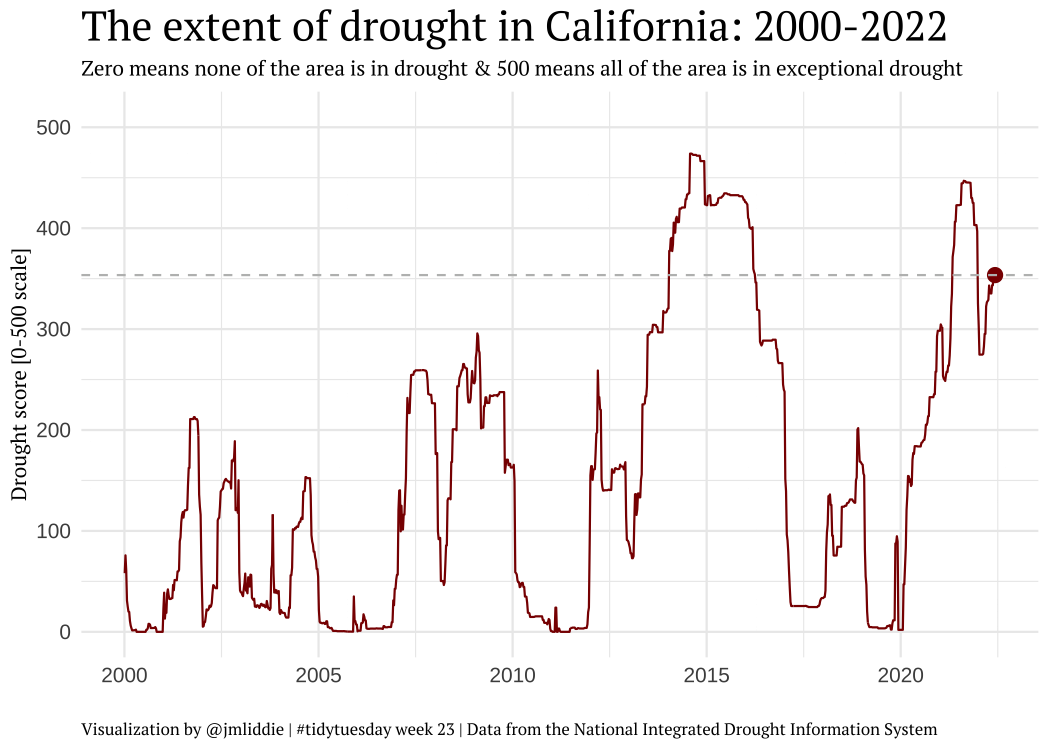
Other examples (pt 4)
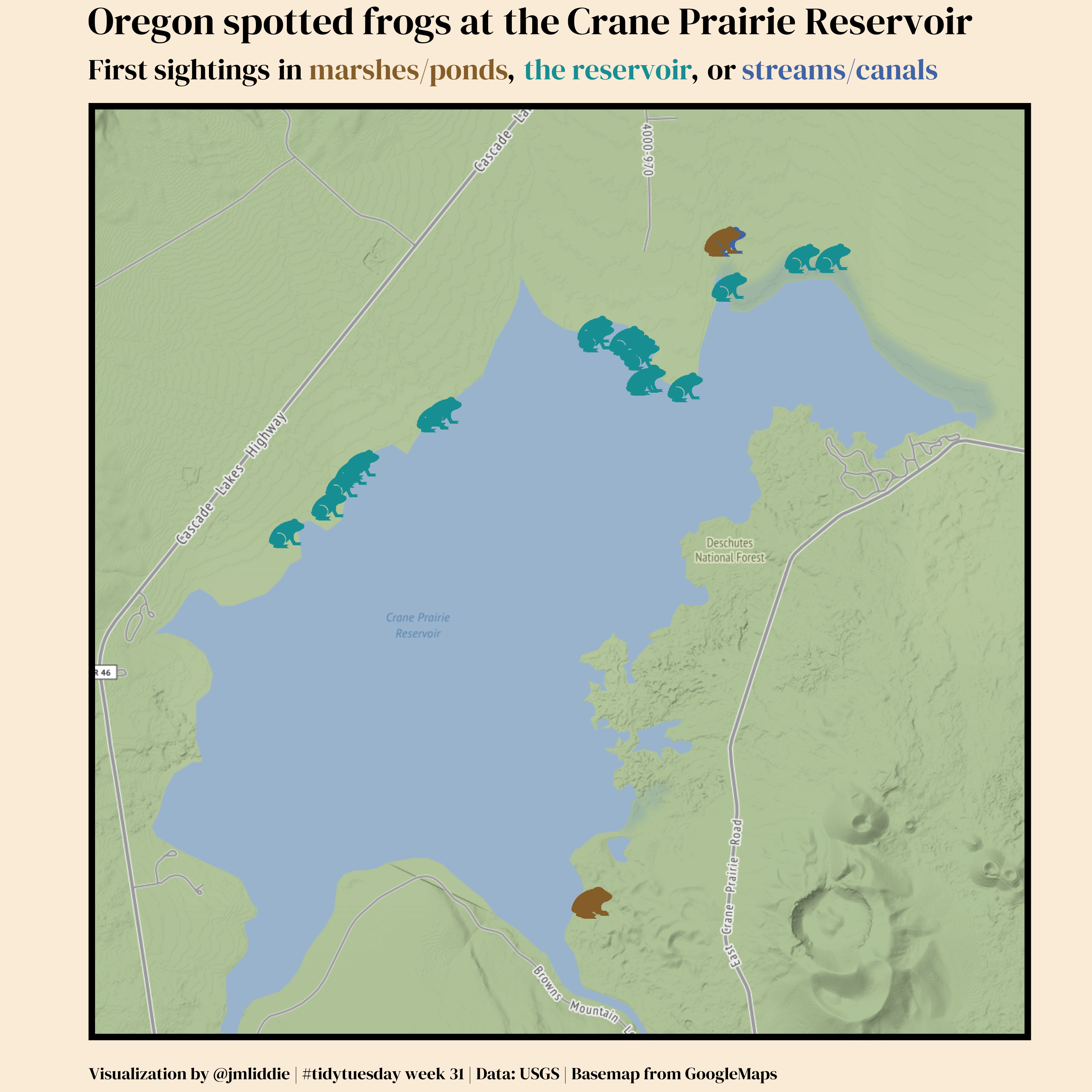
Key packages: sf, ggimage, ggmap
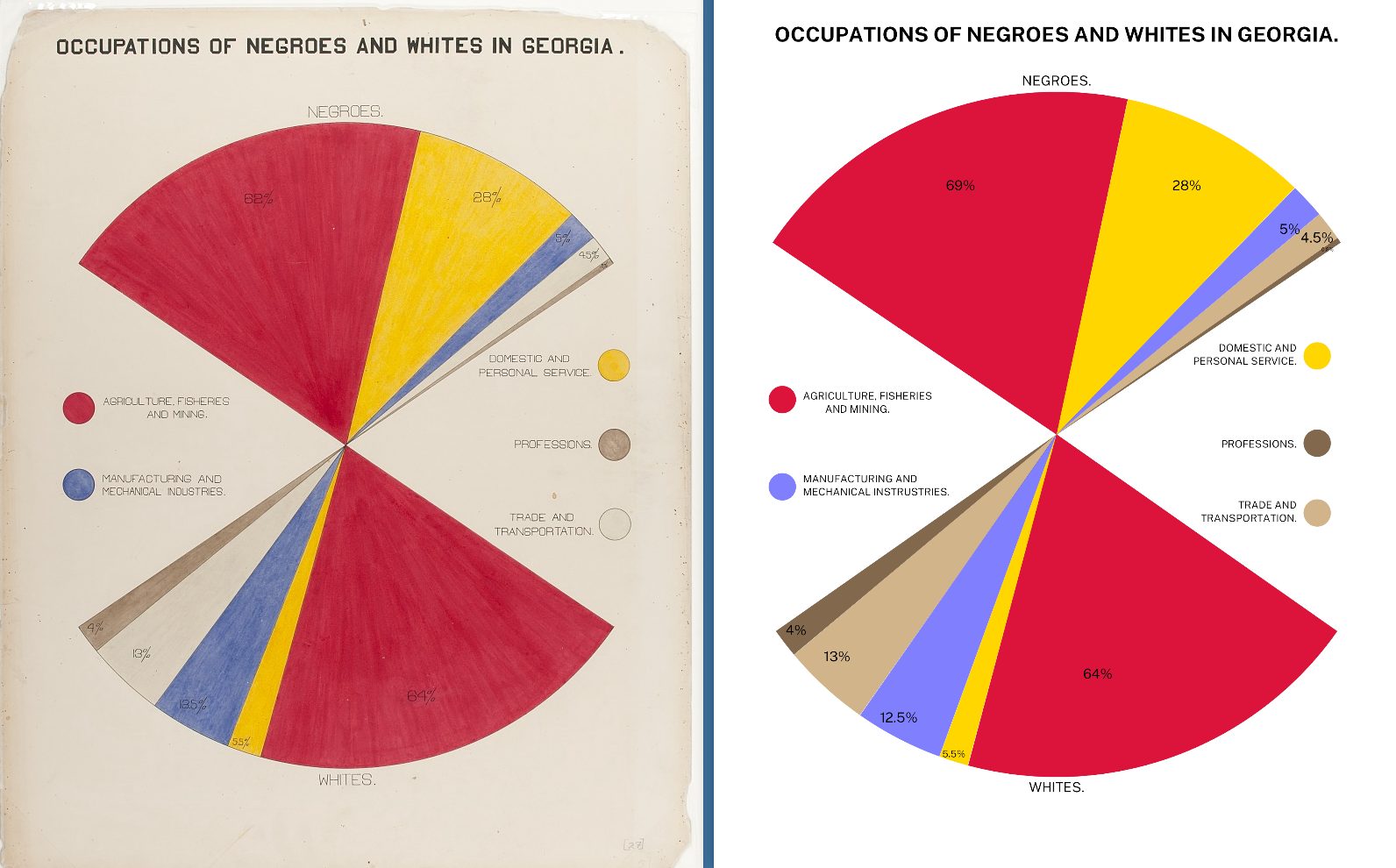
WEB Du Bois data portraits (pt 1)
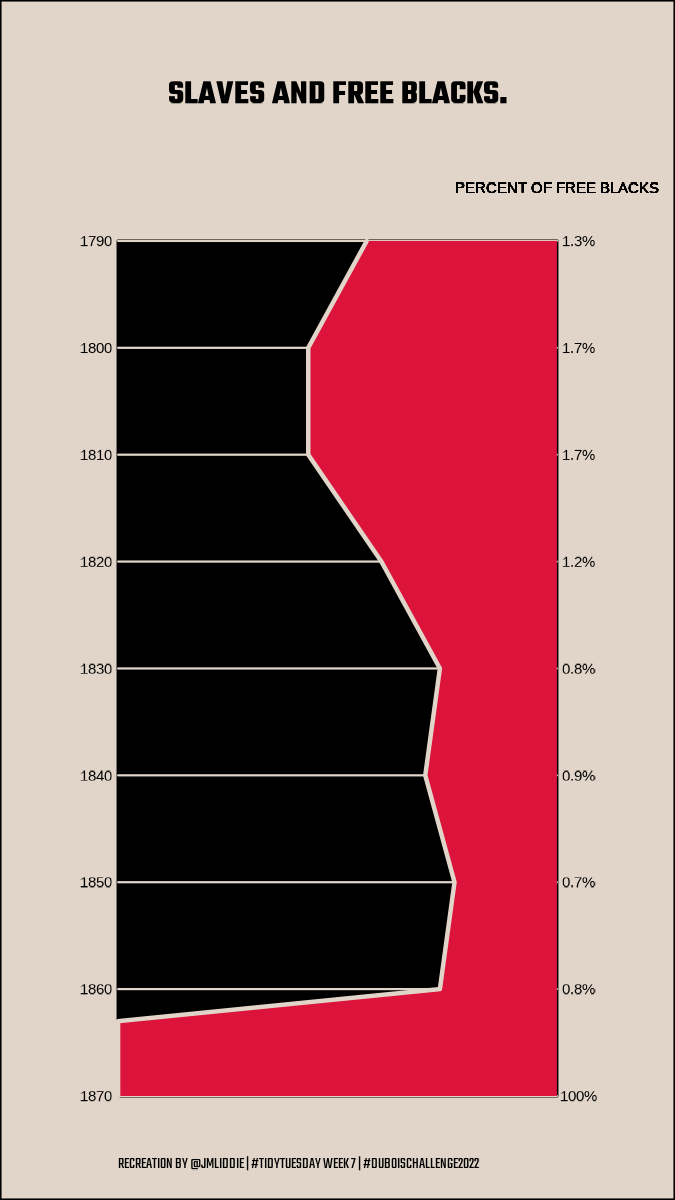
WEB Du Bois data portraits (pt 2)
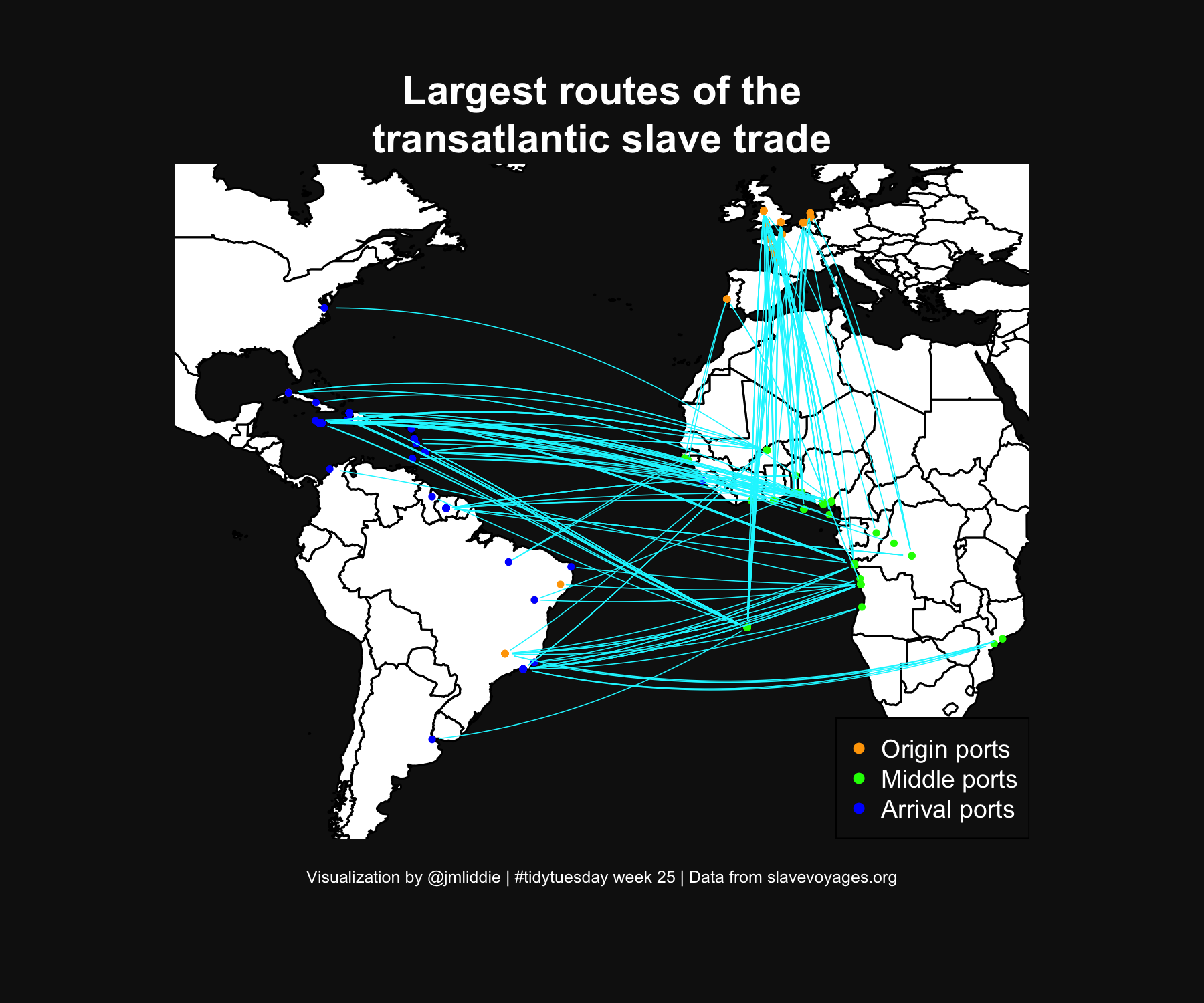
Other examples (pt 5)
Key packages: geosphere, ggmap
Other examples (pt 6)
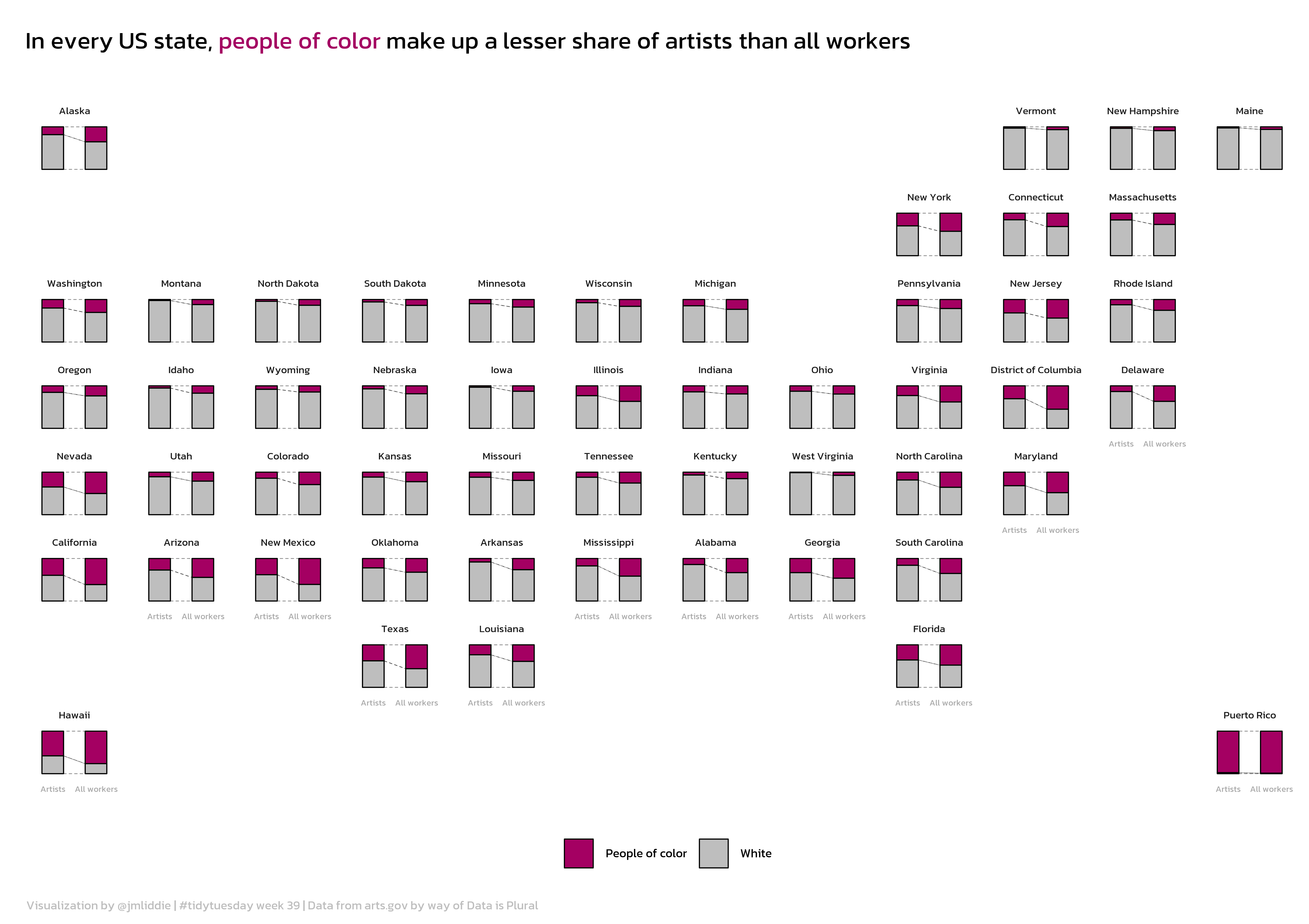
What is geofacet?
geofacetis a package developed by Ryan Hafen to display a sequence of plots (like normalfaceting) but within a structure that preserves the original geographical orientation
Many other regions are supported!
There are 216 grids available in the latest version of geofacet and users can submit their own directly using grid_submit()!
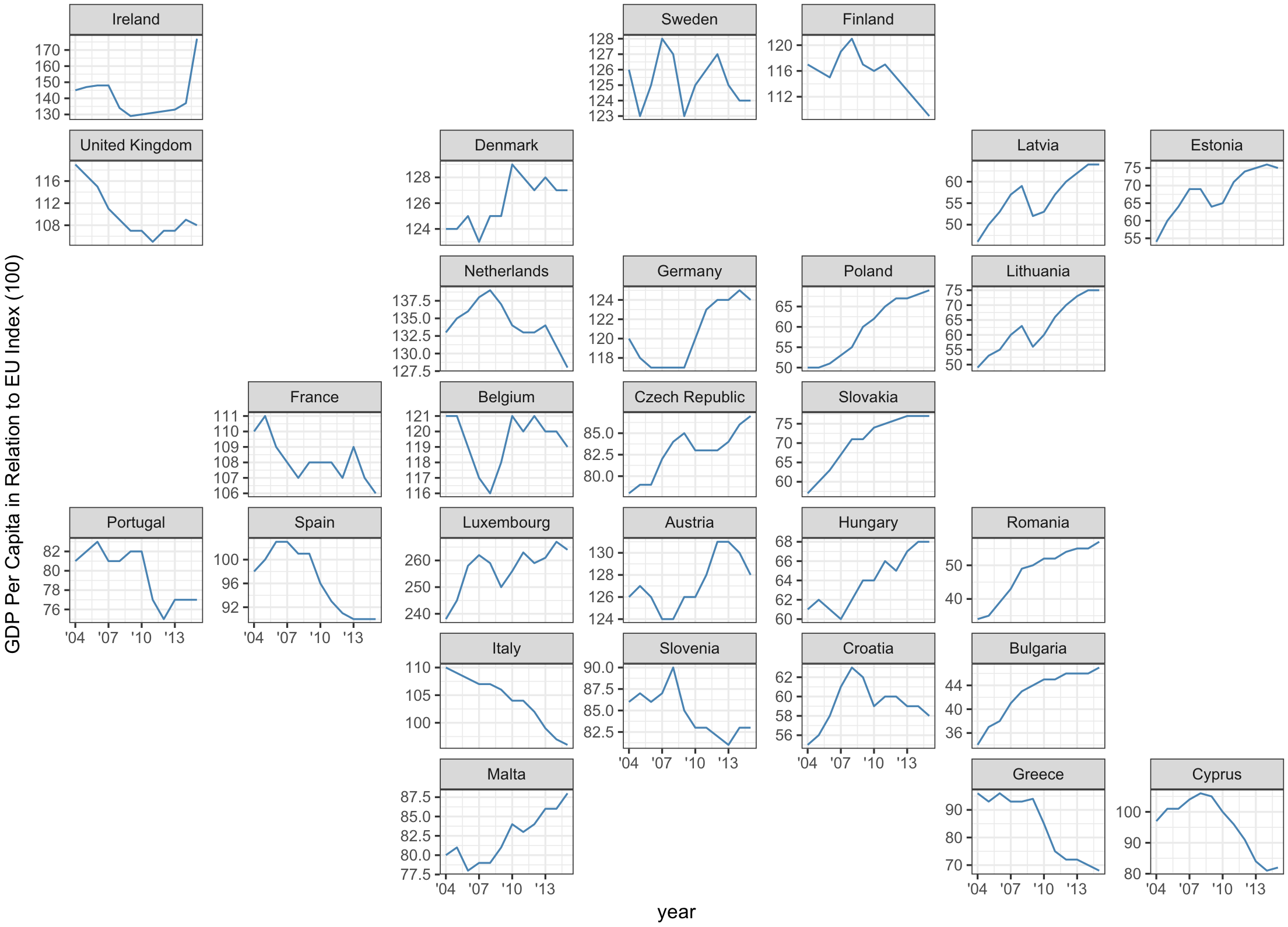
Let’s work through an example live
